
This series of blog posts which I have converted from Youtube videos. I personally have really enjoyed these videos so in order to textually document them, these are essentially some screenshots and rough notes organised.
This particular post is based on the awesome Anjana Vakil JSConf EU 2017 talk. It can be found on the link below: https://www.youtube.com/watch?v=Wo0qiGPSV-s
What Are Immutable Data Structures?
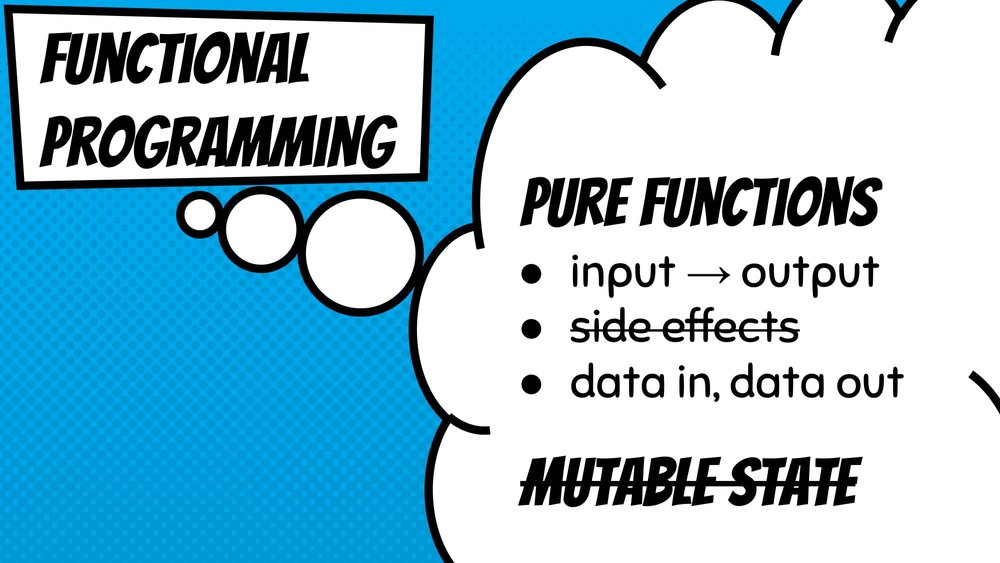
Functional programming is used when implementation of imperative and object-oriented programming starts to become a headache. In functional programming, programs are conceived as just pure functions, meaning that they compute the same output always for the same input. Side effects like changing things in the console or global state are not relatable in functional programming. In fact, they are simply used to take data in, transform the data and send the data out. The important aspect that helps in avoiding these side effect is immutable data – data that is once created can never change. Immutability allows us to do some things pretty easily, however, it does make doing some things difficult.
Mutability and Immutability

Mutability causes a lot of issues as we have to manage who is changing what and where constantly, and have the knowledge of how it is affecting the code overall. This causes a lot of overhead to manage the state and might also cause bugs in the code in case the change was not accounted for in the code and now it has ruined it. To avoid these issues, immutability is introduced. In immutable variants, once the data is created it just sits, unchanging for forever. If anyone wants to add any changes to it, what can be done is that you make a copy of the data and modify it as per your specification. However, because of copying everything again, even for the smallest of modifications, the code starts running pretty slow and takes up a lot of extra memory. So basically, it wastes time and space more because of copying.

To avoid this issue, an alternate solution is introduced when for when handling immutable data. Immutable Data Structures! Immutable Data Structure is a term that is used a lot, especially when a reference to functional programming is made or also in terms of React.
Immutable Data Structures is simply any data structure that is immutable, once it’s created it stays the same and cannot be changed. However, term persistent data structures is used interchangeably with the immutable data structure, even though they both are slightly different from each other. While immutable data is forever unchanging, persistent data is data that gives us some kind of access to old versions. So, even if the persistent data has been modified, the old version of it still exists and is accessible.
There are also partially persistent data, which can be looked at and accessed but can not updated or modified, only the current version of the data can be modified. And then there is fully persistent data structure where we can access any of the past version of the data and update it.
Persistent Immutable Data Structures

What we will discuss is persistent immutable data, that allows us access to its previous versions. For example, if we are using an array for an immutable data, we can switch its structure to a tree with leaves containing the values of the array and being joined by the upper nodes until the root node is reached. So, to change the value of any leaf in this immutable data structure, instead of copying the whole thing, we will simply copy the particular leaf and modify and then simply connect it to other leaves with a different root node. This method of changing the paths and assigning a new root node is called path copying. And hence, everything is not copied but simply shared between the two versions, it allows us to save a lot of memory space and allow us to reuse the parts of the original version that did not change. This process of sharing is called structural sharing because unchanged parts of the original version are shared with the new modified parts.


TRIE
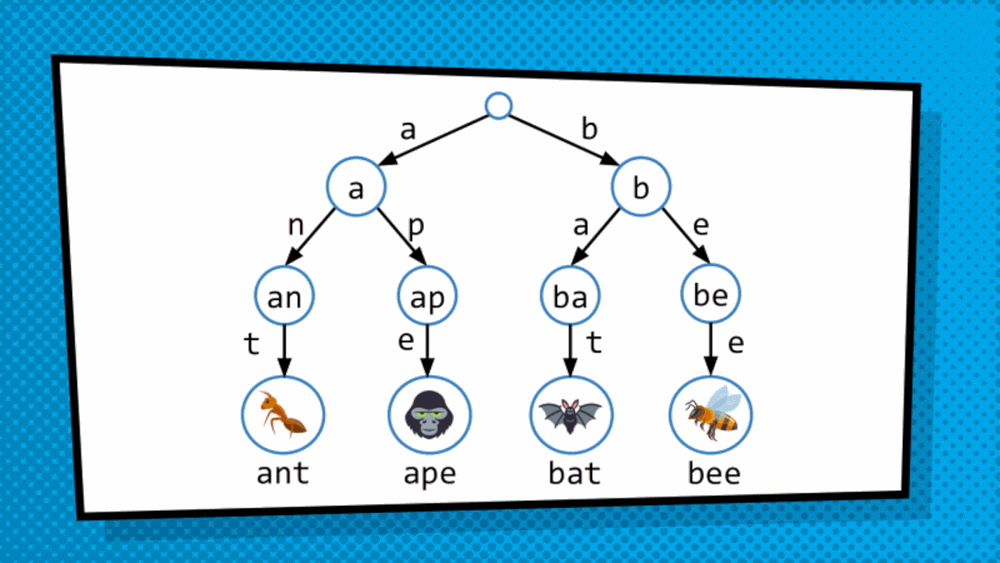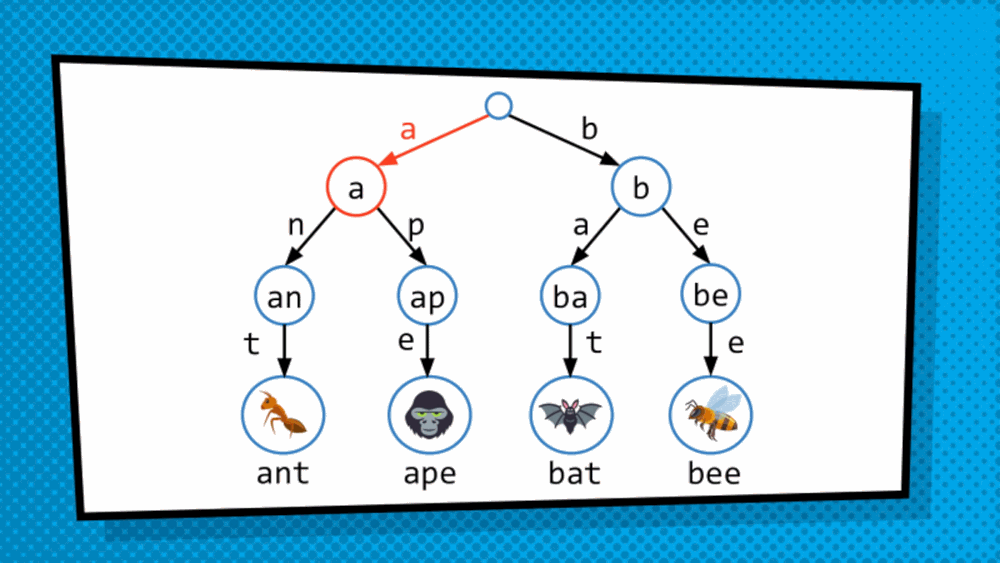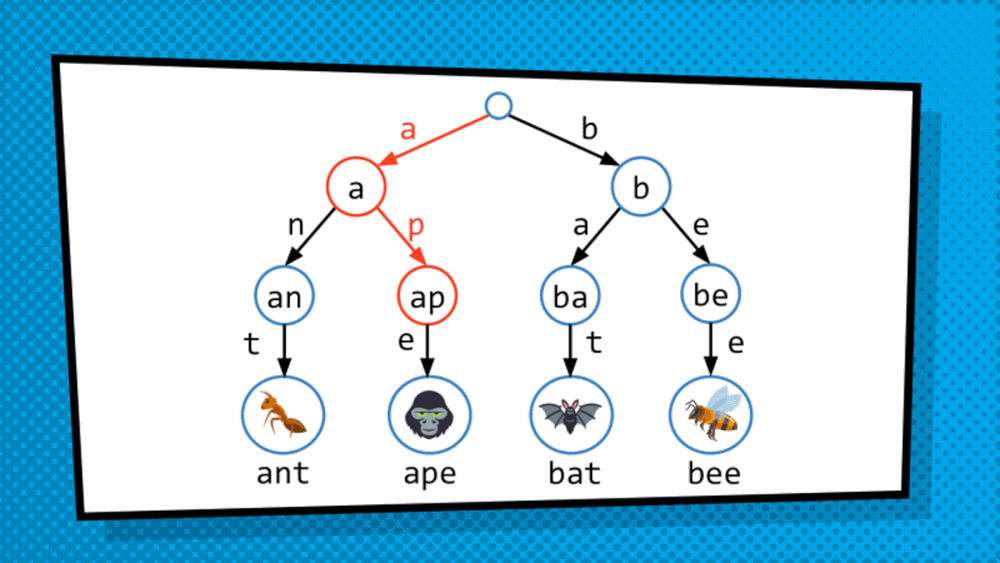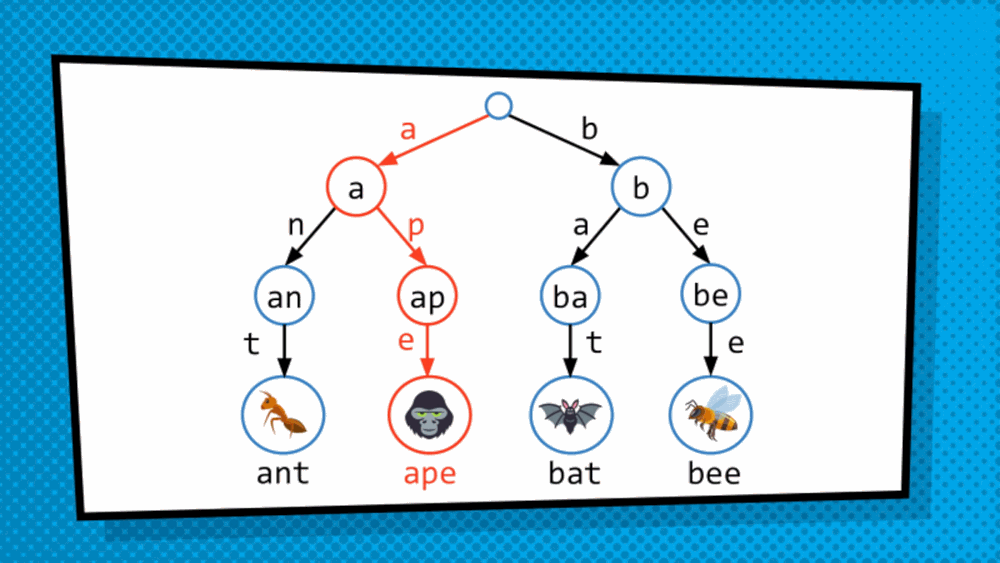
How do we get at the value saved in the data structure? So, the structure discussed above is not a simply tree but is, in fact, T-R-I-E “trie”, originated from the word retrieval. Trie is a type of tree where leaves hold the values of the data, and the paths from the root to the leaves represent the keys associated to that data. As we just converted an array to a trie format, to traverse the trie we are dependent on indices. So, we will treat the index as binary and then traverse the trie bit by bit. Mostly, in this case, right side is assigned 1 while the left side is assigned 0. So, to get to 101 for example, we go to the side of 1 then 0 then 1 and then choose the available data.
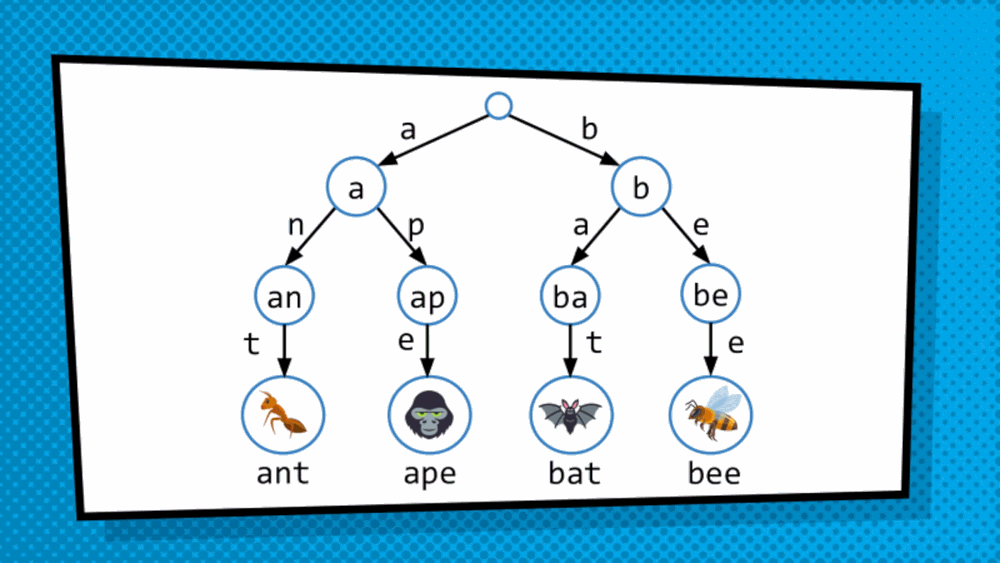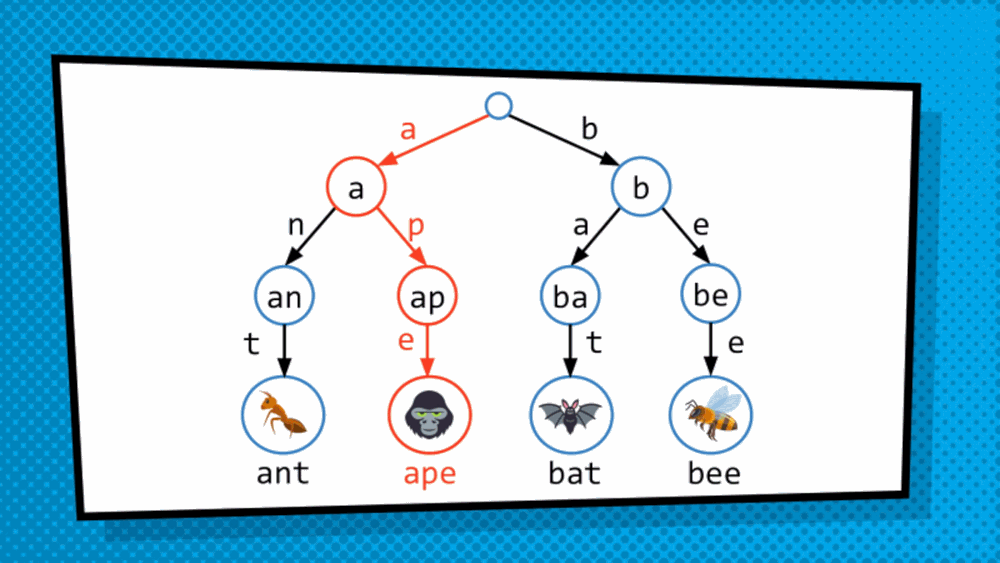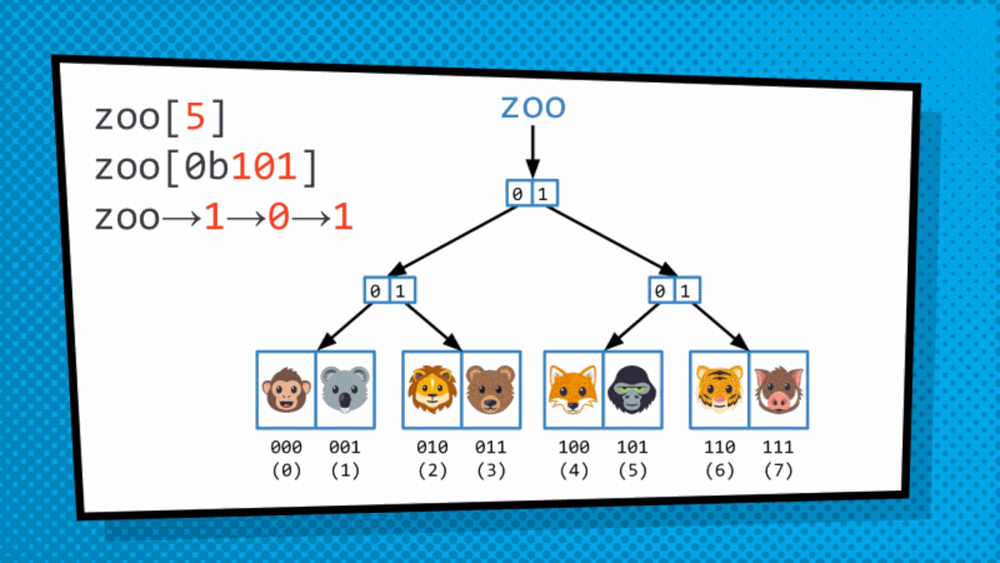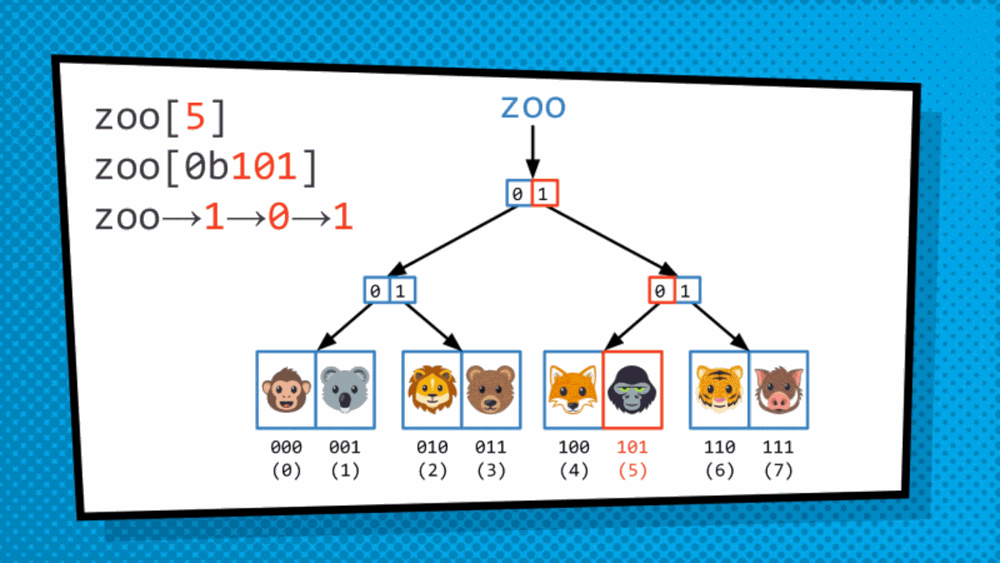
This allows us to quickly traverse the trie even when structural sharing is done to more efficiently represent the copy of the modified data structure.

The trie does not even have to be a binary trie necessarily, in fact usually used trie have 32 ways branching as it is more effective. It helps especially with large numbers because to traverse those with just binary trie can make our trie very, very long which is impractical. So, adding to the branches instead of levels makes the trie more manageable and can be traversed easily.
Bitmapped Vector Trie

In case we do not want to deal with integer indices, but objects associated with arbitrary keys as in non-integers as keys. In this case, our data/object is represented by letters for example instead of a number.

In this scenario, to traverse the trie, we will hash the key to get a number associated to specifically the key. Then the hash is converted to binary to descend the trie as before.
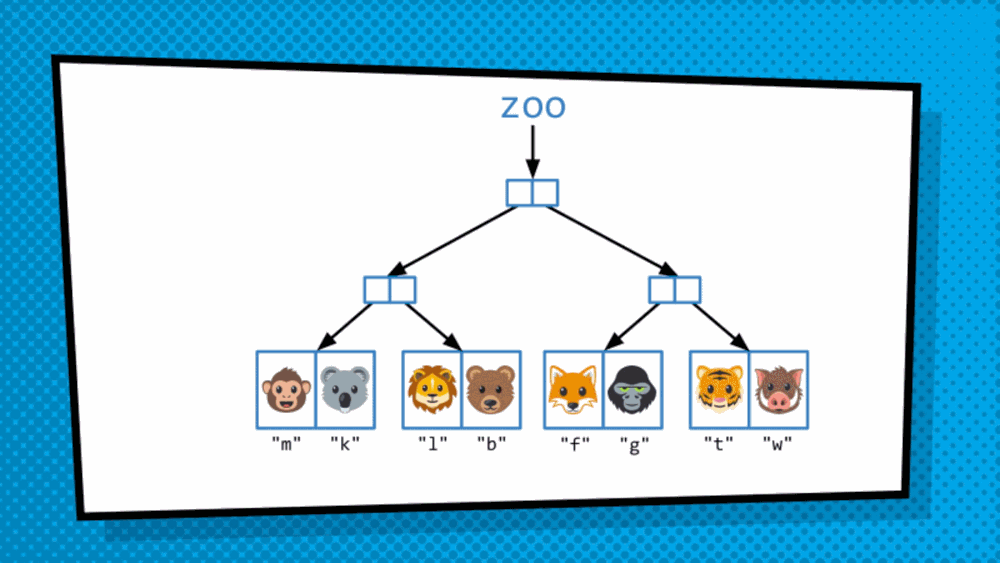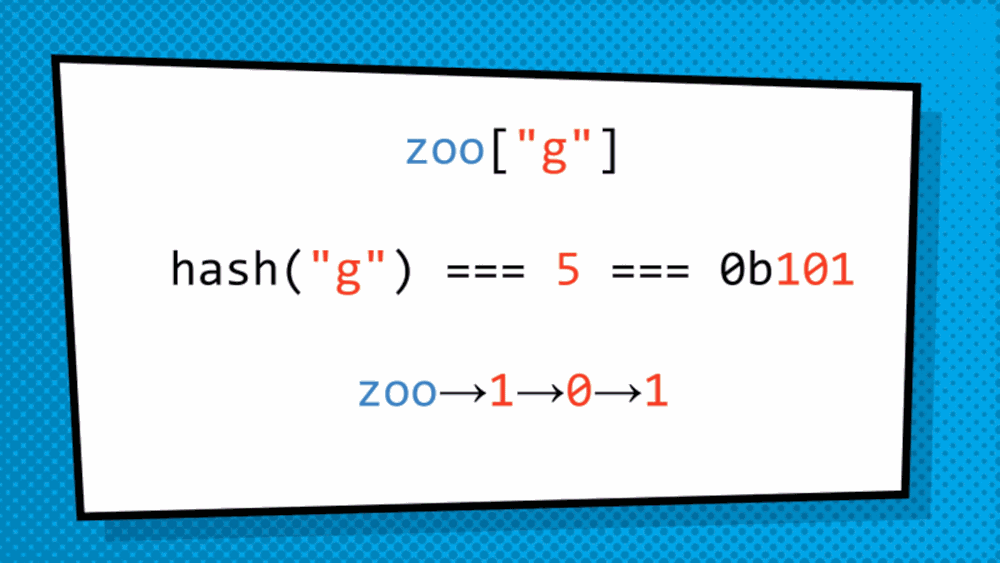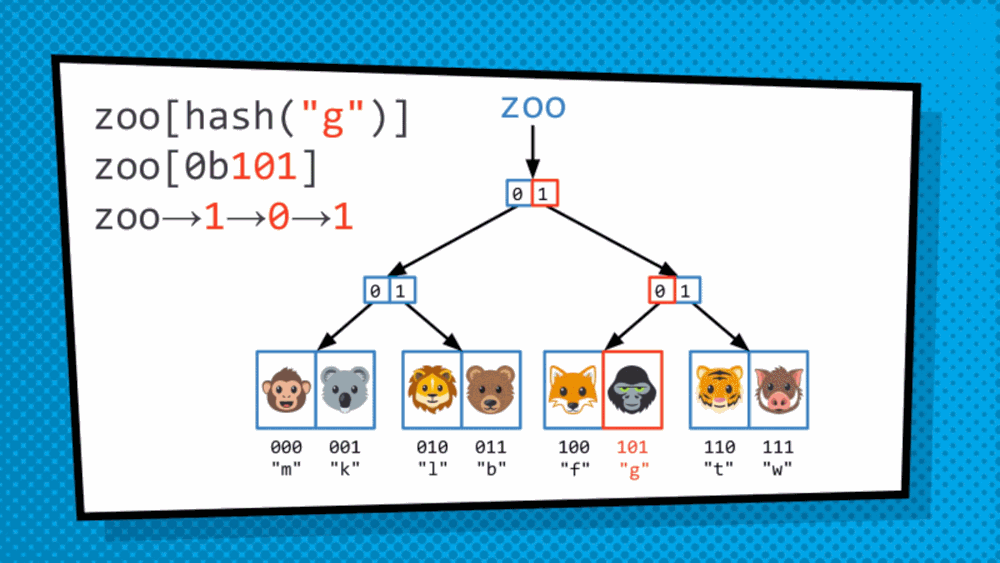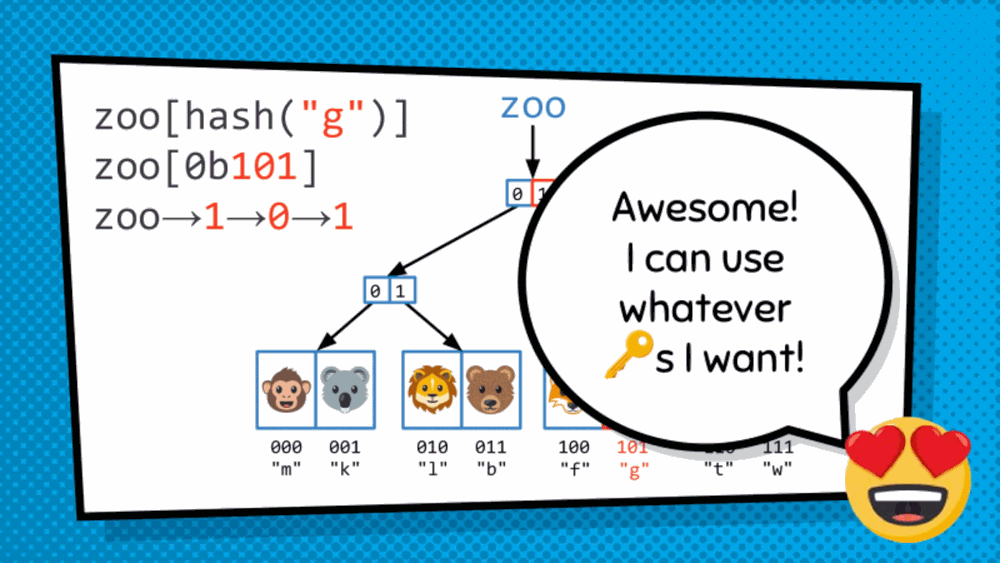
Why are they helpful to handle the immutability used when doing Functional JavaScript?
JavaScript has some great libraries to help us use these immutable data structures off the bat. Some of the solutions available are
– Mori.
Mori is a port of Clojure Script that allows us to leverage the implementation of these data structures from closure script which targets JavaScript from the comfort of vanilla JavaScript, without any added complications. Mori has a bit of a functional language feel to it as its API is functional.
– Immutable.js.
This library was put out by Facebook, and this is the JavaScript implementation of these data structures. Although its API is objective oriented style because of native JavaScript feels in it, but it is introducing new data structures continuously instead of replacing immutable data.
Differences between Mori and Immutable.js:

How to implement Immutable Data Structures in JavaScript?
Here are code snippets from the libraries which create and allow vector immutability.
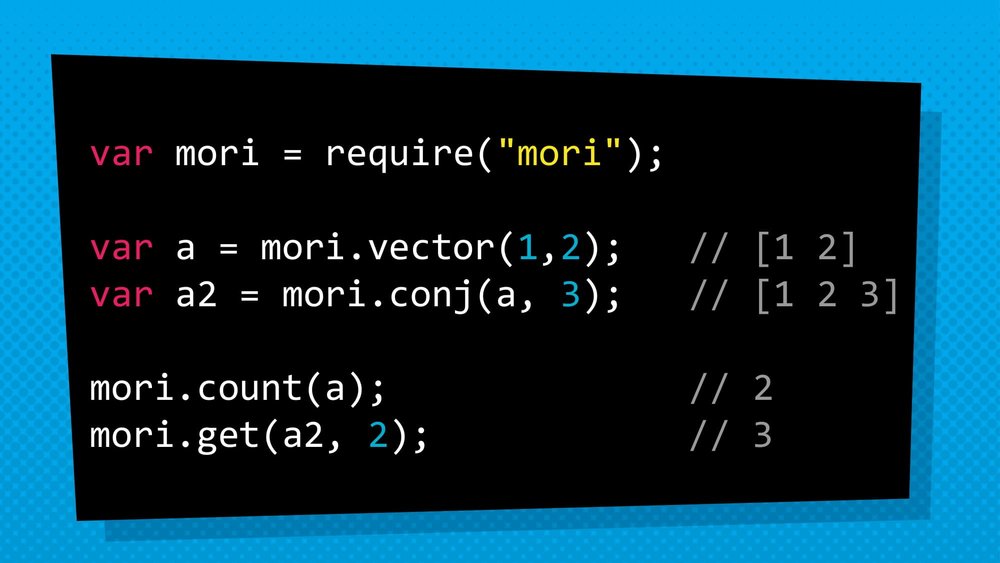
Mori
var mori = require(“mori”); var a = mori. vector (1, 2); // [1 2] var a2 = mori. conj (a, 3); // [1 2 3] mori. count(a); // 2 mori. get (a2, 2); // 3
in this snippet, we have got a vector named a, containing integer 1 and 2. To push something on it, function conj is used. In this function, the original copy a is passed along with what needs to be added (in this case ‘3’). This changes the original data structure [1 2] to new data structure [1 2 3], although it looks different than normal JavaScript Arrays as it Clojure Script Vector instead.

Both can be used interchangeably, however. The new data structure can be caught by the new vector a2, and it can be proved that the original data structure did not change by passing a through the count function and counting the number of things in it. It can also prove that the new version does indeed contain the third thing by accessing the item at index 2 using get function.
Immutable.js

To do the same thing in Immutable.js, here is a code snippet.
var Imjs = require(“immutable”); var a = Imjs. list. of (1, 2); // [1, 2] var a2 = a. push (3); // [1, 2, 3] a. size; // 2 a2. get (2); // 3
Here we have used Imjs. list. of to make an array however it is not a normal JavaScript array but is an immutable.js list. This list is called a, and if we require to add something to the new version of a called a2 we use the dot method notation a. push (3). This, however, still does not change a but simply returns a new version of a and capture it as a2.

To prove that a has not changed, a. size tells us its still 2 and when we try to get the item at 2 from a2, we get three meaning the new version is available at a2.
Hash map
var mori = require(“mori”); var o = mori. hashmap (“a”, 1, “b”, 2); // {“a” 1 “b” 2} var o2 = mori. assoc (o, “a”, 3); // {“a” 3 “b” 2} mori. get (o, “a”); // 1 mori. get (o, “a”); // 3
Hash maps are used to represent the key values we may be using. In this snippet, we have created an object o which has mori. hashmap data structure associating “a” with 1 and “b” with 2. If we require to change one of these keys, we can use assoc function to pass original map o and change the association of “a” from 1 to 3 in the new version o2. To prove that the original has not changed, and the new version is indeed in o2, we can use get function.
Sources:
https://speakerdeck.com/vakila/immutable-data-structures-for-functional-javascript