
We have built a rule set for our client PolicyInPractice which determines the benefits given to people in the UK. The rule set has been written in Javascript and runs on NodeJS. One usual scenario which we run through often is taking a big data set from one of the local authorities and running it through the ‘engine’ to analyze outputs and measure an effectiveness of the policy. These datasets tend to be fairly big (ranging from a few thousand to about a hundred thousand) so running them through the engine usually takes a while.
Following is the engine’s simple UI
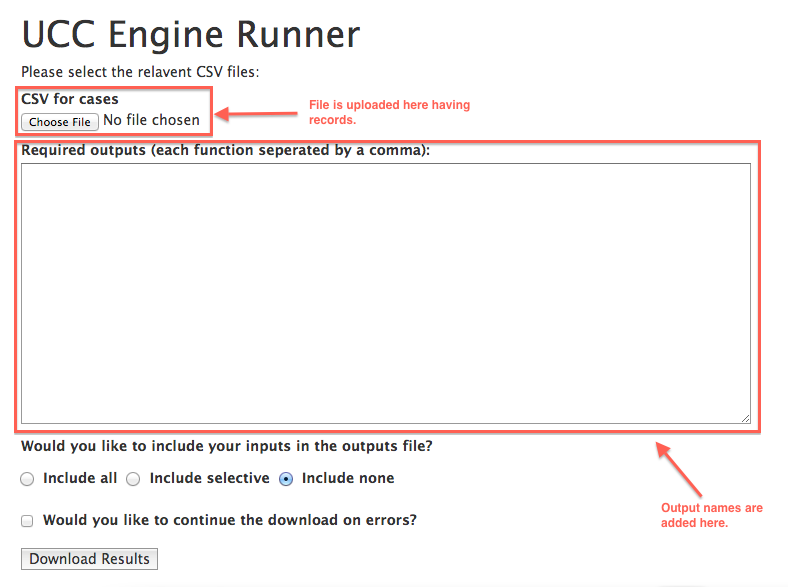
One of the requirements from our client was to reduce this time. We significantly reduced time by moving to the cloud and using a machine with several cores (e.g. the c4.4xlarge with 16 cores on AWS EC2). This meant that for every record in the file being uploaded, we would want it to run on a separate thread. This meant diving into concurrency.
Luckily, concurrency was something we had always kept in mind from the start. The whole engine was designed to be without any “shared variables” and “global variables”. Since calculations were simple, instead of caching them (and getting issues with using stale values) we simply recalculated them. This allowed us to keep the engine very simple and lightweight, with the average calculation taking under 100ms.
So most of the work was already done, all we needed was a library which would allow us to run each calculation in a separate thread. We experimented with several libraries including the JXCore and web-workers for Node. However, we ended up using the built-in child process module since it was very simple and did the required task.
There were two challenges we came across while setting up the project:
1. Since the calculations were computationally intensive, a thread had to be kept free to render the view and show the progress.
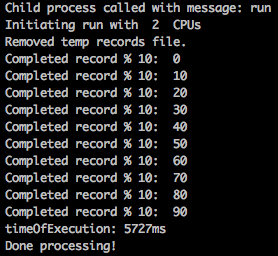
2. There were thousands of records the setup had to first stream in the rows, then queue them and finally work on them one by one. For this, we went with the Mailbox approach where every thread has its mail box and the file parser loops over each thread passing the records as they are streamed in.
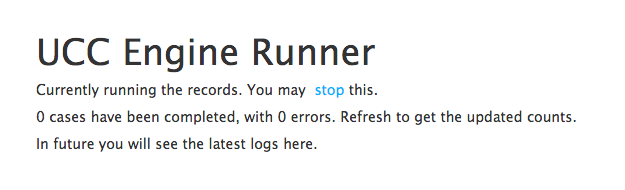
Finally, we added the feature to stop parsing in the middle if requested by the user. This meant setting a flag on all the threads so they would complete their current computation and then stop. Once all of them are stopped, the main dispatcher thread would terminate safely and redirect the user to the download page.
While engine is running the process following option is shown in the UI with an option to stop the process in the middle:
Also the progress is shown on console:
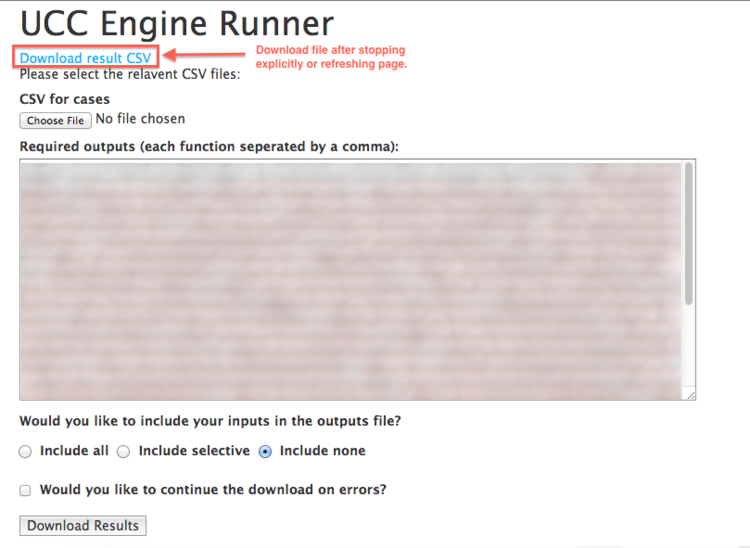
When you press stop or refresh the page (and calculation is completed) you would finally get the link to download the result file.
Running an input file (with about 50 outputs) of 100,000 records took around 50 minutes on a 4-core machine without threading. With our new setup, it came down to 15 minutes. Running it on the 16-core EC2 instance was much better, brining the time required to under 5 minutes.
Another interesting problem we encountered while testing on a Windows based machine was that the threads would get stuck if the timeout was not set between finishing one record and starting the next. The message to the parent thread never got sent and after a few records the threads would stop working altogether. I’m not sure why this happened only on Windows, however the timeout (50ms) does the trick which we are using for now.
If you can think of a better way to implement this using concurrency, pleas do let us know!
We are also looking for more exciting projects like this, if you are looking for some developer support contact us!